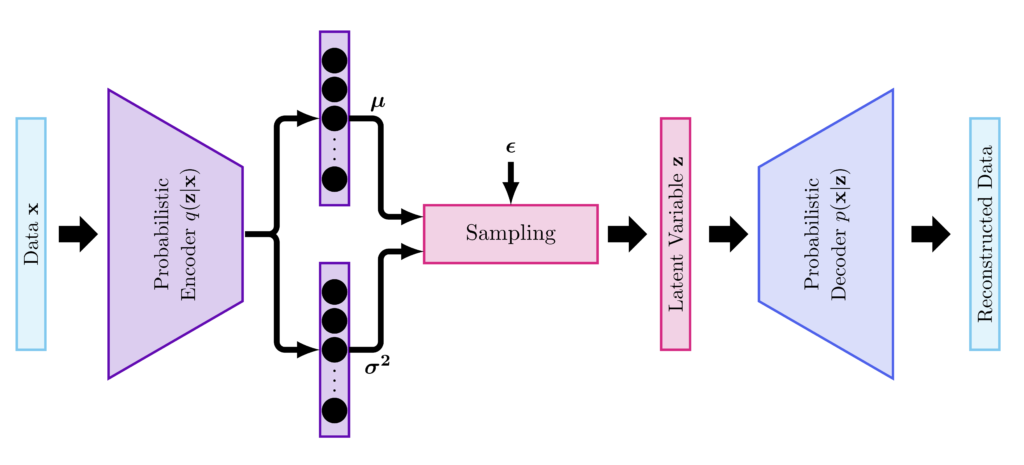
class VariationalAutoEncoder(Model):
”’
Combines the encoder and decoder into an one model for training and adds the KL regularization term to the loss.
”’
def __init__(
self,
original_dim,
intermediate_dim=64,
latent_dim=32,
name=“vae_autoencoder”,
**kwargs
):
super(VariationalAutoEncoder, self).__init__(name=name, **kwargs)
self.loss_tracker = tf.keras.metrics.Mean(name=‘loss’)
self.original_dim = original_dim
self.encoder = Encoder_CNN(latent_dim=latent_dim)
self.decoder = Decoder_CNN()
self.shape = (28, 28, 1)
def call(self, inputs):
# Encoder
z_mean, z_log_var, z = self.encoder(inputs)
# Adding the KL term to the loss
kl_loss = – .5 * backend.sum(1 + z_log_var –
backend.square(z_mean) –
backend.exp(z_log_var), axis=-1)
self.add_loss(backend.mean(kl_loss))
# Decoder
reconstructed = self.decoder(z)
return reconstructed
def train_step(self, data):
x, y , _ = utils.unpack_x_y_sample_weight(data)
with tf.GradientTape() as tape:
x_decoded = self(x)
loss = self.compute_loss(y = y, y_pred = x_decoded)
self.optimizer.minimize(loss, self.trainable_variables, tape=tape)
return self.compute_metrics(x, y, x_decoded, None)
def compute_loss(self, x=None, y=None, y_pred=None, sample_weight=None):
loss = backend.sum(backend.mean(losses.binary_crossentropy(y, y_pred), axis = 0))
loss += tf.add_n(self.losses)
self.loss_tracker.update_state(loss)
return loss